%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# High Resolution
Chinese Picks

Chatimg
ChatIMG is an AI image generation platform utilizing ChatGPT 4o technology, focusing on transforming photos or ideas into Studio Ghibli-style artwork. It employs an advanced diffusion model, supporting ultra-high-resolution image generation, suitable for professional art creation. The product aims to enable anyone to create high-quality visual content to meet personal and commercial needs, with flexible pricing strategies to suit different users.
Image Generation
50.0K
Flashvideo
FlashVideo is a deep learning model focused on efficient, high-resolution video generation. Its staged generation strategy first creates a low-resolution video, which is then enhanced to high resolution using an upscaling model. This approach significantly reduces computational costs while maintaining detail. This technology holds significant promise for video generation, especially in scenarios requiring high-quality visual content. FlashVideo is suitable for a variety of applications, including content creation, advertising production, and video editing. Its open-source nature allows researchers and developers to customize and extend its functionality.
Video Production
54.4K
Prompt Depth Anything
Prompt Depth Anything is a method for high-resolution and high-precision depth estimation. This method unlocks the potential of depth foundational models through prompting techniques, using iPhone LiDAR as a cue to guide the model in generating precise depth measurements of up to 4K resolution. Additionally, it introduces a scalable data pipeline for training and has released a more detailed ScanNet++ dataset with depth annotations. The main advantages of this technology include high-resolution and high-precision depth estimation, along with benefits for downstream applications such as 3D reconstruction and generalized robotic grasping.
3D Modeling
48.0K
Sana 1600M 1024px MultiLing
Sana is a text-to-image framework developed by NVIDIA, capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at remarkable speeds while maintaining robust text-image alignment, making it deployable on laptop GPUs. The Sana model is based on linear diffusion transformers, utilizing pre-trained text encoders and spatially compressed latent feature encoders, supporting Emoji, Chinese, and English inputs, as well as mixed prompts.
Image Generation
46.1K
Sana 1.6B
Sana-1.6B is an efficient high-resolution image synthesis model based on linear diffusion transformer technology, capable of generating high-quality images. Developed by NVIDIA Labs, it employs DC-AE technology and boasts a potential space of 32 times, allowing it to run on multiple GPUs and deliver powerful image generation capabilities. Renowned for its efficient image synthesis and high-quality output, Sana-1.6B is a significant technology in the image synthesis field.
Image Generation
52.2K

Sana
Sana is a text-to-image framework capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at an incredibly fast speed while maintaining strong text-image alignment and can be deployed on laptop GPUs. The core design of Sana includes a deep compressed autoencoder, a linear diffusion transformer (DiT), a small language model as a decoder-only text encoder, and efficient training and sampling strategies. Compared to modern large diffusion models, Sana-0.6B is 20 times smaller and measures throughput over 100 times faster. Additionally, Sana-0.6B can be deployed on a 16GB laptop GPU, generating images at 1024×1024 resolution in less than 1 second. Sana makes low-cost content creation feasible.
Image Generation
52.2K
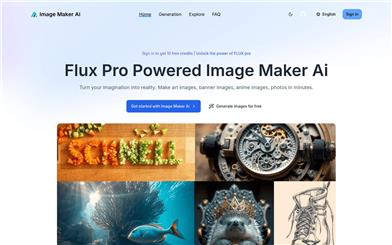
Image Maker AI
Image Maker AI is an AI-based image generation platform that leverages advanced transformer models and the latest AI research from BlackForestLabs, catering to a wide range of needs from high-end professional projects to speedy personal use. The technology features 1.2 billion parameters and multiple model variants, including FLUX.1 [Pro], [Dev], and [Schnell], optimizing prompt adherence, detail, and output diversity. Image Maker AI allows users to input text prompts, select styles, and generate high-resolution, detail-rich, realistic images suitable for various applications, from personal projects to professional uses. All images generated by Flux are royalty-free, allowing use for personal or commercial purposes without copyright concerns.
Image Generation
52.2K
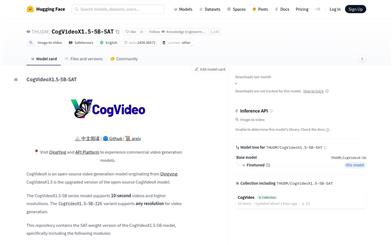
Cogvideox1.5 5B SAT
CogVideoX1.5-5B-SAT is an open-source video generation model developed by the Knowledge Engineering and Data Mining team at Tsinghua University. It is an upgraded version of the CogVideoX model, supporting the generation of 10-second videos as well as videos in higher resolutions. The model includes modules such as Transformer, VAE, and Text Encoder, enabling video content generation based on textual descriptions. With its powerful video generation capabilities and high-resolution support, the CogVideoX1.5-5B-SAT model provides a robust tool for video content creators, with broad application prospects in education, entertainment, and commercial fields.
Video Production
70.4K
FLUX 1.1 Pro Ultra
FLUX 1.1 [pro] is a high-resolution image generation model capable of producing images up to 4MP while maintaining a generation time of just 10 seconds per sample. The FLUX 1.1 [pro] – ultra mode can generate images at four times the standard resolution without sacrificing speed, and performance benchmarks show it generates images over 2.5 times faster than comparable high-resolution models. Additionally, the FLUX 1.1 [pro] – raw mode offers creators pursuing realism a more natural and less synthetic image generation effect, significantly enhancing diversity in characters and the authenticity of natural photography. The model is competitively priced at $0.06 per image.
Image Generation
86.4K
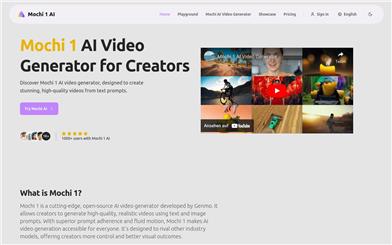
Mochi 1 AI
Mochi 1 is a cutting-edge open-source AI video generator developed by Genmo, allowing creators to generate high-quality, realistic videos using text and image prompts. With its superior prompt adherence and smooth motion effects, Mochi 1 makes AI video generation accessible to everyone. It aims to compete with other industry models, offering creators more control and better visual outcomes.
Video Production
60.7K
IC Light V2
IC-Light V2 is a series of IC-Light models based on Flux, featuring a 16ch VAE and native high-resolution technology. This model shows significant improvements over its predecessors in terms of detail preservation and stylized image processing. It is particularly suited for applications that require stylization while maintaining image details. Currently, this model is released for non-commercial use, primarily targeting individual users and researchers.
Image Generation
106.5K

Hallo2
Hallo2 is a facial animation technology based on a latent diffusion generative model, generating high-resolution, long-duration videos driven by audio. It expands upon Hallo's capabilities by incorporating several design improvements, including the generation of long videos, 4K resolution outputs, and enhanced expression control through textual prompts. Key advantages of Hallo2 include high-resolution output, long-duration stability, and enhanced control via textual prompts, making it significantly beneficial for generating diverse and rich portrait animation content.
AI image generation
68.7K
Cogview3
CogView3 is a text-to-image generation system built on a cascaded diffusion framework. This system decomposes the high-resolution image generation process into multiple stages, adding Gaussian noise to low-resolution outputs, which initiates the diffusion process from these noisy images. CogView3 surpasses SDXL in image generation, featuring faster generation speeds and higher image quality.
AI image generation
65.1K
Follow Your Canvas
Follow-Your-Canvas is a video upscaling technology based on a diffusion model that can generate high-resolution video content. This technology addresses GPU memory limitations through distributed processing and spatial window merging while maintaining both spatial and temporal consistency in the video. It excels in large-scale video upscaling, significantly enhancing video resolution (e.g., from 512 x 512 to 1152 x 2048) while delivering high-quality and visually pleasing results.
AI video generation
50.2K
Fresh Picks
FIFO Diffusion
FIFO-Diffusion is a novel inference technique based on pre-trained diffusion models for text-conditioned video generation. It enables the generation of videos of unlimited length without training, by iteratively executing diagonal denoising while handling an increasing level of noise across a series of consecutive frames within a queue. The methodDequeues a fully denoised frame from the head, while enqueueing a new random noise frame at the tail. Additionally, latent disentanglement is introduced to reduce the training-inference gap, and future denoising is utilized to leverage the benefits of forward references.
AI video generation
113.4K
Ttplanet SDXL Controlnet Tile Realistic
This is a SDXL-based ControlNet Tile model trained on the Hugging Face Diffusers dataset and is compatible with Stable Diffusion SDXL ControlNet. It was initially developed for my own realistic model training, used in the ultimate upscaling process to enhance image details. With the right workflow, it can provide good results for high-detail, high-resolution image repair. As most open-source models lack SDXL Tile models, I decided to share this one. This model supports high-resolution repair, style transfer, and image enhancement functions, providing you with a high-quality image processing experience.
AI Image Generation
102.9K

PIXART
PIXART-Σ is a diffusion transformer model that directly generates 4K resolution images. Compared to its predecessor PixArt-α, it offers higher image fidelity and better alignment with text prompts. The key features of PIXART-Σ include an efficient training process, where it evolves from a 'weaker' baseline model to a 'stronger' model by leveraging higher-quality data in a process called 'weak-to-strong training'. Improvements in PIXART-Σ include the use of higher-quality training data and efficient label compression.
AI image generation
483.6K
Clarityai
ClarityAI.cc is a high-resolution image enhancement tool powered by cutting-edge AI technology. It can enhance image details and provide ultra-high resolution. Applicable to a variety of scenes including landscapes, portraits, illustrations, anime, and interior design. Free options are available.
Image Enhancement
89.7K

LGM
LGM is a novel framework for generating high-resolution 3D models from textual prompts or single-view images. Its key insights include: (1) 3D Representation: We propose a multi-view Gaussian feature as an efficient yet powerful representation that can be fused for differentiable rendering. (2) 3D Backbone: We present an asymmetric U-Net as a high-throughput backbone operation for multi-view images, which can be utilized to generate from text or single-view image inputs using multi-view diffusion models. Extensive experiments demonstrate the high fidelity and efficiency of our method. Notably, we achieve high-resolution 3D content generation while maintaining fast rendering speed for 3D objects, even when training resolution is increased to 512x512.
3D Modeling
73.1K
Demofusion
DemoFusion is a high-resolution image generation solution that does not require high costs. By utilizing progressive upsampling, skip residual and expansion sampling mechanisms, DemoFusion extends open-source generative AI models to achieve higher resolution image generation. It boasts user-friendliness, requiring no parameter adjustment or substantial memory, making it accessible to a wide user base. DemoFusion can seamlessly integrate with other applications based on latent diffusion models, enabling controllable high-resolution image generation.
AI image generation
96.0K
Luosiallen LCM
Luosiallen/latent-consistency-model is a model for synthesizing high-resolution images. It uses a small number of inference steps to generate images with good consistency. The model supports custom input prompts and parameter adjustments, enabling the creation of realistic artwork and portraits.
AI image generation
237.6K
Mimiko
Mimiko is an application that can upgrade and restore old photos. It operates on images according to user input to generate high-resolution graphics. It can also remove image backgrounds, generate graphics from detailed descriptions, and provide answers from specific aspects of an image. Mimiko promises to offer even more features in the future.
AI image generation
65.7K
AI Image Enhancer & Upscaler
AI Image Enhancer & Upscaler is a tool that utilizes advanced AI technology to transform your images into stunning masterpieces. It can enhance image quality, upscale image resolution, achieving clear, fine, and flawless results. Not only can it be used for personal photo enhancement, but it is also suitable for image processing needs in various fields such as professional photography, cartoon/anime creation, e-commerce stores, real estate, and more. The product pricing is flexible and caters to different user groups.
Image Editing
653.6K
AI Image Upscaler By Upscale.media
Leveraging powerful AI technology, our tool quickly upscales images and enhances details, improving image quality to meet both personal and commercial needs. We preserve image texture and enhance it in a realistic manner. We offer options to upscale your images by 2x or 4x while maintaining the integrity of texture and detail. Whether you're a professional, e-commerce vendor, or individual user, our tool makes it easy to enhance your image quality.
AI image enhancement
87.8K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.8K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.2K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M